
GR00T-H-N1.7 — TUM SonATA Franka Fine-Tune
Fine-tuned checkpoint of nvidia/GR00T-H-N1.7 on the TUM SonATA robotic ultrasound subset of the Open-H Embodiment dataset.
The model controls a Franka Panda robot performing ultrasound probe manipulation tasks (placement, transverse scanning, anatomical navigation) on abdominal, thyroid, and arm phantoms.
Demo
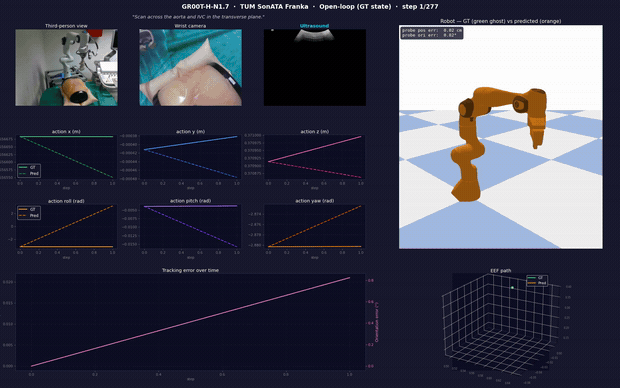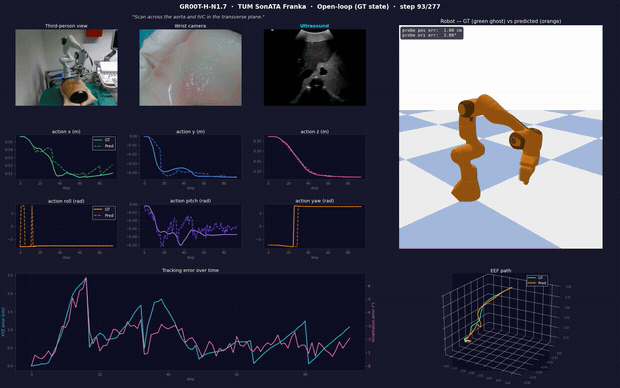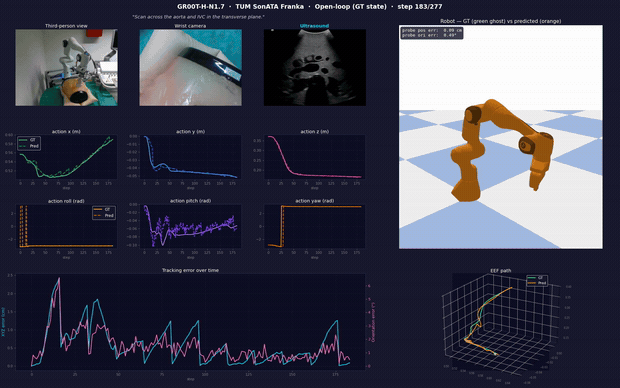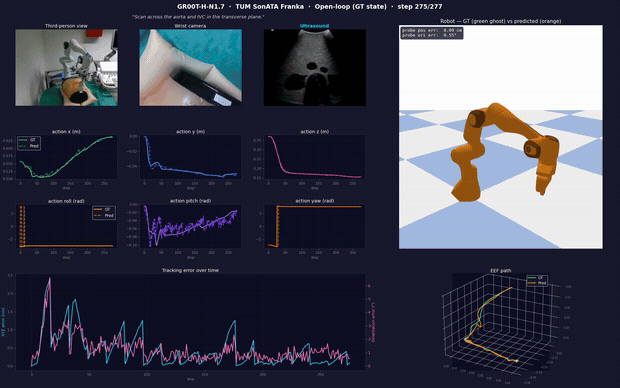
Open-loop inference: probe positioning → transverse-plane traversal. One frame shows the live cameras (third-person / wrist / ultrasound), predicted vs. ground-truth action curves, position and orientation tracking error, the commanded Franka motion (GT green-ghost vs. predicted orange), and the EEF path. Full video + reproducible pipeline: Hemanth21k/world-models.
Model Details
| Property | Value |
|---|---|
| Base model | nvidia/GR00T-H-N1.7 |
| Backbone (frozen) | NVIDIA Cosmos-Reason2-2B (Qwen3-VL); features @ layer 16, dim 2048 |
| Action head | flow-matching Diffusion Transformer (4 denoising steps) |
| Embodiment | TUM_SONATA_FRANKA |
| Robot | Franka Panda + ultrasound probe |
| Task | Robotic sonography — probe placement, scanning, navigation |
| Action space | 9D REL_XYZ_ROT6D (relative EEF pose, 50-step horizon @ 30Hz) |
| Conditioning | single-frame / Markovian (no observation history) |
| State inputs | 7D joint angles + 6D force/torque |
| Camera inputs | Third-person view · Wrist camera · Ultrasound image |
| Language | Natural language instructions per episode |
Training Details
| Setting | Value |
|---|---|
| Dataset | Open-H Embodiment — TUM SonATA |
| Episodes | 2,397 total · 1,677 used for training |
| Frames | 633,604 total @ 30 Hz |
| Hardware | 6 × NVIDIA RTX A6000 (49 GB) |
| Training steps | 16,000 (~0.8 epoch; stopped early — see notes) |
| Global batch size | 192 (32 per GPU) |
| Learning rate | 8e-4 peak, cosine decay, 5% warmup |
| Optimizer | AdamW (weight decay 1e-5) |
| Tuned components | Projector + diffusion action head (backbone frozen) |
| Framework | DeepSpeed ZeRO-2, PyTorch 2.7 |
| Final loss | ~0.025 at step 16,000 (from 1.57; ~0.039 → 0.025 over the last 6k steps) |
Training Notes
A gradient spike (loss ≈ 55, grad norm ≈ 155) occurred at approximately step 2,500 when the learning rate reached its peak. Training recovered automatically via gradient clipping. For future runs at this batch size, a peak learning rate of 4e-4 or lower is recommended.
Training was stopped at step 16,000 (≈0.8 epoch). The loss was still decreasing but decelerating, and test-split error was already strong (see Evaluation); a longer / lower-LR / multi-epoch run is left as future work.
Evaluation
Held-out test split (482 episodes). Per-step error of the predicted vs. ground-truth EEF
action, swept over the re-inference horizon H. Position = XYZ L2; orientation = geodesic
angle; baseline = zero-motion (hold last observed pose). Seeded for reproducibility.
| Mode | H | Pos (cm) | Rot (°) | Baseline pos (cm) | Baseline rot (°) |
|---|---|---|---|---|---|
| Open-loop | 1 | 0.09 | 1.07 | 0.19 | 0.53 |
| Open-loop | 8 | 0.37 | 1.47 | 0.84 | 2.37 |
| Open-loop | 16 | 0.64 | 2.15 | 1.55 | 4.39 |
| Open-loop | 50 | 1.61 | 4.92 | 4.24 | 12.70 |
| Rollout | 16 | 4.72 | 14.14 | 1.55 | 4.39 |
- Open-loop (true state each step): sub-cm to ~6 mm, beating the zero-motion baseline ~2–2.6× on position; degrades gracefully as re-inference gets sparser.
- Rollout (predicted EEF pose fed back as the reference state): errors compound (~4 cm / ~14°). Note this rollout is hybrid — only the EEF pose is fed back; cameras and the rest of the state come from the dataset (a true closed loop needs a world model).
Full sweep (all horizons, both modes, std/median/max) and the evaluation code are in the GitHub repo.
Usage
from gr00t.model.policy import Gr00tPolicy
policy = Gr00tPolicy(
model_path="Hemanth21k/GR00T-H-N1.7-TUM-SonATA-Franka",
embodiment_tag="TUM_SONATA_FRANKA",
denoising_steps=4,
)
See the GR00T-H getting started guide for full inference setup, including dataset format and processor configuration.
Dataset
Training data comes from the NVIDIA PhysicalAI Open-H Embodiment dataset, specifically the TUM SonATA subset:
Ultrasound/tum/computer_aided_medical_procedures_camp_lab/sonata_all_update/sonata_all
The SonATA dataset is a robotic sonography collection from TUM's Computer Aided Medical Procedures (CAMP) Lab, containing synchronized ultrasound imaging, external RGB cameras, contact force/torque measurements, robot joint state, and natural language instructions collected from abdominal, thyroid, and arm phantoms.
| Subset | Episodes | Tasks |
|---|---|---|
| SonATA_abdomen | 1,533 | 287 |
| SonATA_arm | ~1,107 | — |
| SonATA_thyroid | ~780 | — |
Acknowledgements
This work was conducted at the Quantitative Bio Imaging Lab (QBIL) at The University of Texas at Dallas.
Research reported in this publication was supported in part by the National Cancer Institute of the National Institutes of Health under Award Numbers R01CA288379 and R01CA204254, and by the Cancer Prevention and Research Institute of Texas (CPRIT) under Award Number RP240289. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Computing resources were provided by the QBIL Lab GPU cluster at UT Dallas.
- GitHub: Hemanth21k/world-models
- Contact: satyasaihemanth.p@utdallas.edu
License
The fine-tuned weights inherit the NVIDIA Open Model License from the base GR00T-H-N1.7 model. The training code is released under Apache-2.0 via Hemanth21k/world-models.
Citation
If you use this model, please cite:
@software{pasupuleti2026worldmodels,
author = {Pasupuleti, Hemanth},
title = {world-models: Unified interface for testing and extending
world model architectures for Physical AI},
year = {2026},
url = {https://github.com/Hemanth21k/world-models},
note = {Quantitative Bio Imaging Lab (QBIL), The University of Texas at Dallas.
Supported by NIH R01CA288379, R01CA204254 and CPRIT RP240289.}
}
- Downloads last month
- 94